SEO対策には、
- コンテンツ対策
- 外部対策(被リンク対策)
- 内部対策(この記事のことです)
※順不同
があります。
そしてコンテンツの対策には①から順番に・・・
があります。
理想は、SEOの全体像を書いた以下の記事を読んでからこの記事を読むことですが、

この記事を読み終えてからでもOKです。
では、本題に入りますがこの記事は「内部対策」について網羅的に書かれたものです。
この記事を読めば、他のSEO内部対策の記事を読むことしなくても良いと思います。
この記事を読んで理解したならば、さっさと残った対策をして下さい。
但し、この記事は現時点での話なのでGoogleの動向によって変更があれば随時編集します。
また、「SEO対策を知れば稼げる。」は有り得ません。
あくまでもSEO対策とは、コンテンツを正しくGoogleの機会(Googlebot)も認識させる為の手段です。
検索順位で1位を取っても、もっと言えばコンテンツが良くても
マーケティングが下手だったら全く稼げません。
その理由は以下の記事で。

でも、SEO対策はインターネットでビジネスをする上で意識しなければならない手段であることには変わりません。
この記事は、以下を前提条件にしています。
- ドメインを取得済み
- サーバーを契約済
- サイトをWordPressで作成済みで、http(s)://(www.)(ドメイン) でアクセスできる
以上を満たしてれば、このまま読み進んで下さい。
まだドメインの取得・サーバー契約をしていない方は、
この

という記事を読んで下さい。
fa-checkサイトをWordPressで作成済みで、http(s)://(www.)(ドメイン) でアクセスできる
のように、サイトをWordPres以外の手段で作成していてもこの記事は有益ですので
全然このまま読み進んで頂いても構いません。
また、記事内の画像が小さくて見えにくい!(ハズキルーペ的な)場合は、
クリックすると拡大されて表示されます。
内部対策とは?
-
- クローラーが、webサイトやwebページのコンテンツ(文書など)を巡回
- 1.で巡回したコンテンツのインデックス
- インデックスされた情報を元に、アルゴリズムにより順位を決定
※1クロールとは?・・・クローラー(Googleなどの検索エンジンを作る会社が作った、webサイト・webページ
のコンテンツを収集するプログラム)を巡回させること。Googleのクローラーのことを特に、Googlebotと呼ぶ。
※2インデックスとは?・・・webサイト、webページ情報がGoogleのデータベースに登録されること
自分たちの、webサイトやwebページにあげたコンテンツをしっかりと評価して貰って、
適正な順位を付けて貰いたいはずです。
そこで必要なのが、内部対策です。
分かり易く言えば、読書感想が書かれた用紙を例にしますが、
先生に提出するのは当たり前ですが、起承転結を考えて
文章の構成を読み手に分かり易く書こうとしますよね?
良い読書感想文を書けたとしても、文章の構成がぐちゃぐちゃだと
見栄えが悪く大変読みづらくなってしまいます。
同じような意味でwebサイトやwebページにあげたコンテンツの構成、
そしてwebサイトやwebページ自体の構成も、これは
Googleの関係者である人間が検索順位を決めている訳ではなくて、
Googleが定義したアルゴリズムによって決まります。
また、アルゴリズムが機能する為にも、
クローラーにwebサイトやwebページを巡回させる必要もありますし、
更に、巡回しに来たのは良いが、クローラーがその
webサイトやwebページに巡回した時に、

グチャグチャでどんなコンテンツか
分からないニャン!
と判断されてしまっては、例えインデックスされてもその後のアルゴリズムによって、検索順位を落とされます。
人間向けには、
- 正しい日本語
- 誤字脱字を無くす
- 正しい文法
クローラー向きには、以下より詳細に説明しますがhtmlタグを使って、
- どれが重要なキーワードなのか?
- どういう構成になっているか?
などを、クローラーにわかるように伝える必要があります。
以下より、クローラー編とインデックス編に分けて話します。
クローラーの巡回を促す

クローラーの巡回のさせ方は、
- Googleに提供したsitemap.xml、RSS(feed)を通じて巡回させる
- 既にインデックスされたサイトのリンクを通じて巡回させる
この2種類があります。
2.「既にインデックスされたサイトのリンクを通じて巡回させる」については、
という記事に載っていますが、簡潔に言うと
過去に自分で作った他のサイトからの今のサイトへのリンクと
誰かの他サイトからのリンクがあれば、リンクを辿ってクローラーがあなたのサイトに巡回しに来るということです。
この記事では以下より、
1.「Googleに提供したsitemap.xml、RSS(feed)を通じて巡回させる」方法を書きます。
sitemap.xml、RSS(feed)とは、
webサイトのwebページをリスト化したファイルのようなもので、
クローラー向きのサイトマップのことです。
このサイトの、クローラー向きのサイトマップは以下のURLです。
クローラーは通常、既にインデックスされているサイトの被リンクを辿って新たなサイトを巡回します。
※インデックスとは?・・・webサイト、webページ情報がGoogleのデータベースに登録されること
※被リンクとは?・・・他のwebサイトからの、自サイトへのリンクのこと。
しかし、クローラーはwww(ウェブ・Web)上の全てのサイトを巡回はしないので
立ち上げ間もないwebサイトは、クローラーはその存在を知りませんし、
他webサイトからの被リンクもないのでクローラーが巡回してくる確率は下がります。
確かに被リンクをして貰ったり、自分のサイトを自分のSNSアカウントで
紹介するでも良いですが、インデックスされるが遅かったり、漏れがあったります。
その時に、sitemap.xml、RSS(feed)をGoogleなどに送信するとクローラーの巡回を促すと
webページのインデックスの遅延と漏れがなくなります。
sitemap.xml、RSS(feed) などはクローラー(ロボット)向きのサイトマップであるのに対して
目次のように、記事へのリンクが付けられた記事タイトルが並んだものが人間向けのサイトマップと言います。

また、なぜsitemap.xml、RSS(feed)の2種類のサイトマップを送るのかと言いますと、
Google Webmaster Central Blogでは、sitemap.xml、RSS(feed)の
両方をGoogleに送信することを薦めているからです。
こうしてみると、落合さんが「既にアメリカ企業によるIT植民地支配が出来上がっている。」
という発言からもわかるように、SEOで勝つ=Googleに媚を売ると同義ですよね(笑)
脱線しました。
先ずは、sitemap.xmlから説明します。
クローラー向けにsitemap.xmlを作成・送信をし、クローラーを呼ぶ
サイトをワードプレスで作っている場合は、「All in One SEO Pack」か、
「Google XML Sitemap」というプラグインがオススメです。
All in One SEO Pack
管理画面にログインした後、プラグインをインストールして、
All in One SEO Pack > 機能管理 をクリック。
「XMLサイトマップ」をActivateする。
「XMLサイトマップ」が出てきます。
管理画面にログイン > All in One SEO Pack > XMLサイトマップまで表示させてください。
以下より、設定をします。
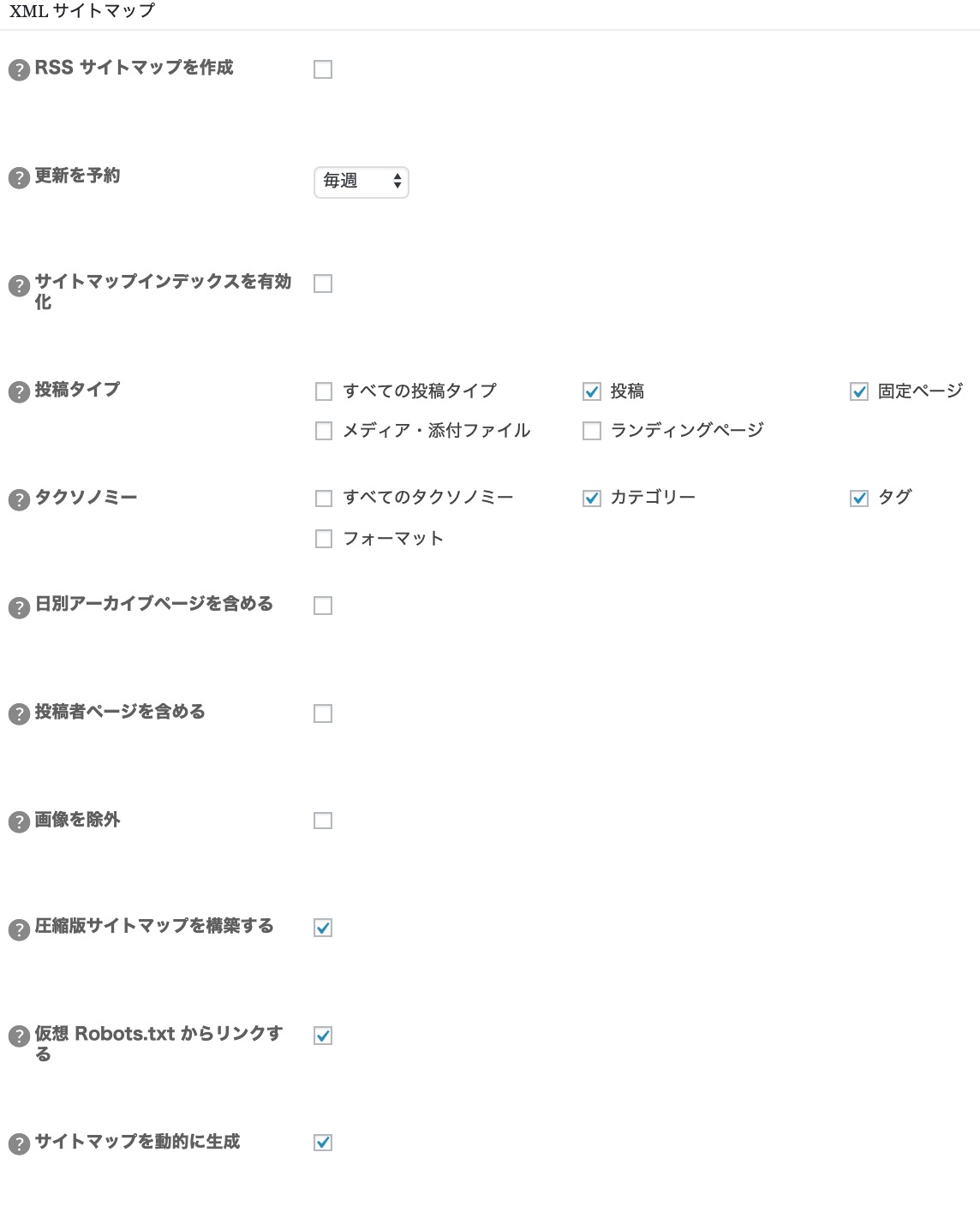
XMLサイトマップ(領域)での設定方法
- RSS サイトマップを作成
ここは、後述する別の方法でRSS(feed)のサイトマップを作成しますので、
チェックは外してください。
- 更新を予約
サイトの更新に合わせて各自で設定してください。
- サイトマップインデックスを有効化
「サイトマップは、50,000以上のURLが含まれているか、ファイルのサイズは5メガバイトを超えている場合に
のみ有効にします。」と書いてあるので、それを満たしてなければ、チェックは外してください。
- 投稿タイプ
投稿と固定ページにチェックを付けます。
- タクソノミー
カテゴリーとタグにチェックを付けます。
- 日別アーカイブページを含める
チェックは外してください。
- 投稿者ページを含める
チェックは外してください。
- 画像を除外
チェックは外してください。
- 圧縮版サイトマップを構築する
チェックを付けます。
- 仮想 Robots.txt からリンクする
チェックを付けます。
- サイトマップを動的に生成
チェックを付けます。
上記をまとめると、以下のスクリーンショットになります。
追加ページ(領域)以降は、そのまま
特に設定を変える必要はありません。
Search ConsoleでXMLサイトマップを送信する
- Google Search Console にログイン。
- プロパティを追加 をクリック。
![Google サーチコンソル プロパティ追加説明画像]()
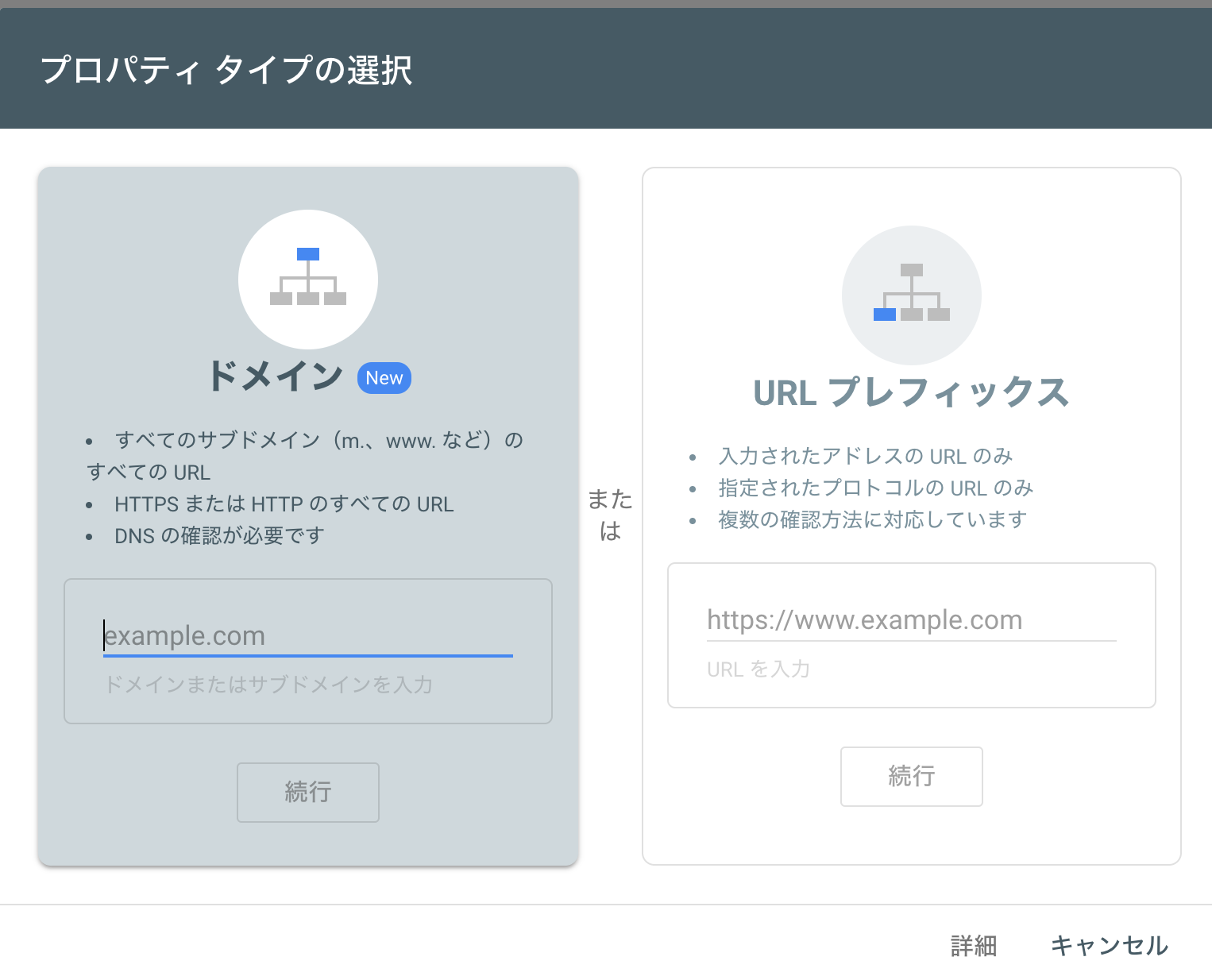
- 左のドメインを選択して、ドメイン”yujiyayamazato.com”などを入力。
![プロパティタイプ ドメインを選択]()
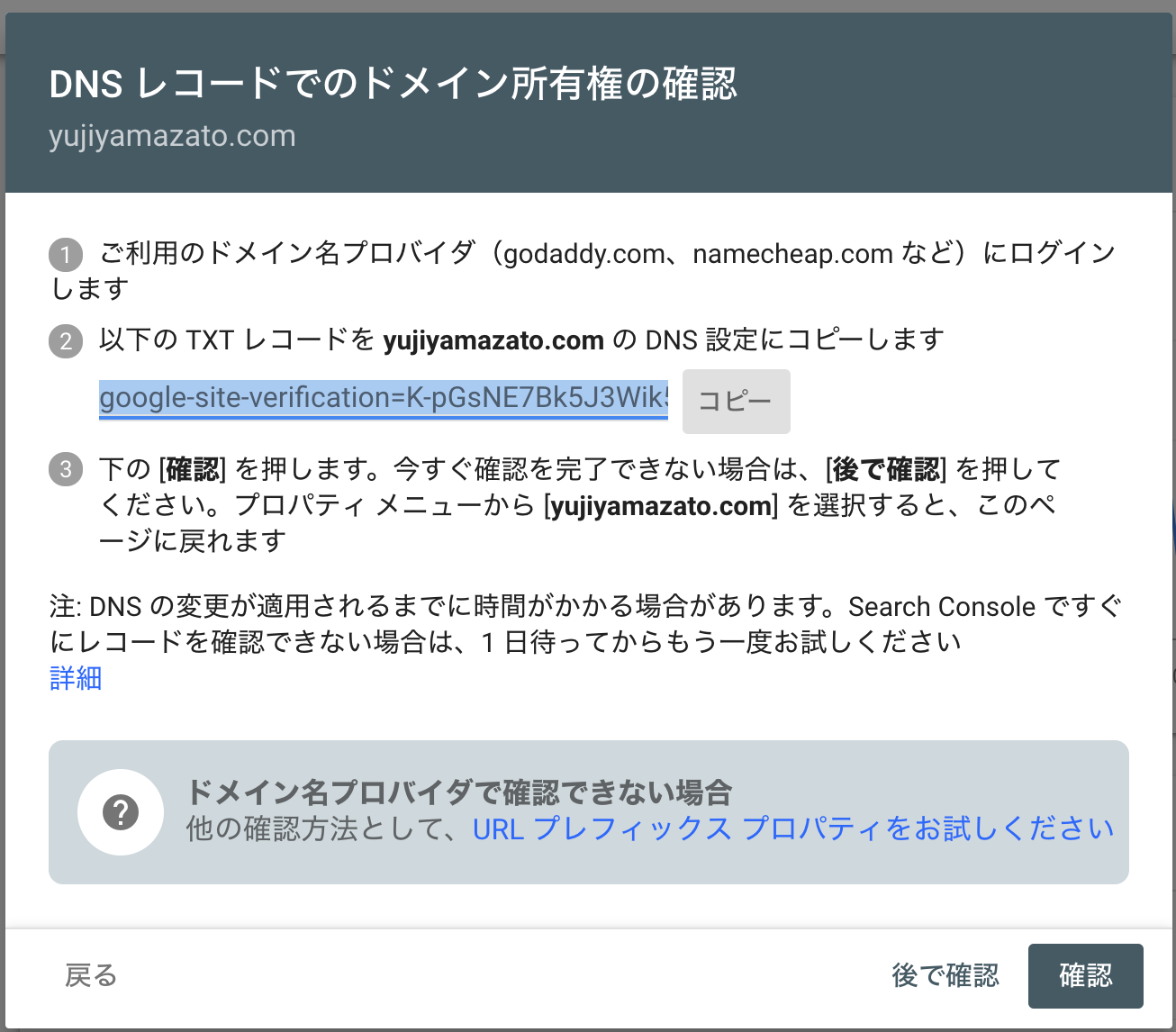
- TXT レコードを、ドメイン名プロバイダ(ドメインを取得したレジストラのこと)にログインして、
DNS 設定にコピぺし、サイトの所有権を確認する。各レジストラでの確認の仕方は、
ドメイン所有権の確認手順を参照。また、左のドメインでサイトの所有権を確認できな場合は、
右のURLプレフィックスで行って下さい。![DNSレコードでのドメイン所有権の確認の説明画像]()
- 「確認」をクリック。ポイントは、所有権の確認をしようとしているドメインのネームサーバーは、
そのドメインを取得したサイト(レジストラ、ドメインプロバイダ)のネームサーバーにした状態で確認をクリックすることです。そうしないと、エラーになってしまいます。確認ができた後は、ドメインのネームサーバをサーバーのものにしておきましょう。例えばお名前.comでドメインを取得したら、サイトの所有権が確認できてからサーバープロバイダがさくらサーバーならば、ドメインのネームサーバーをさくらサーバーに変えてください。 - 管理画面にログイン > All in One SEO Pack > XMLサイトマップ >サイトマップのステータス
に表示された、”XML サイトマップを表示”、”RSS サイトマップを表示”のリンクをコピーして、
Google Search Console > サイトマップ にペーストして送信します。![All in One SEO Pack 説明画像2]()
![xmlサイトマップとRSSをサーチコンソルに追加した画像]()

Google XML Sitemap
同じく、先ずはプラグインをインストールして、設定>XML-Sitemap の順にクリック。
以下、スクショの通り設定して下さい。
基本的な設定(領域)での設定方法

Additional Pages(領域)での設定方法
特に何も設定しません。
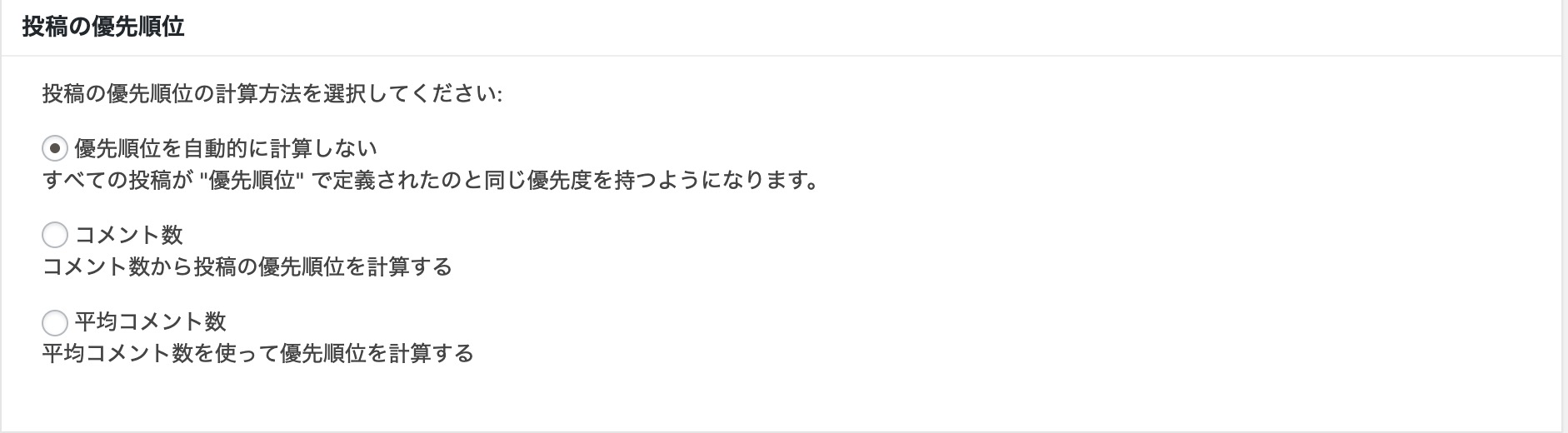
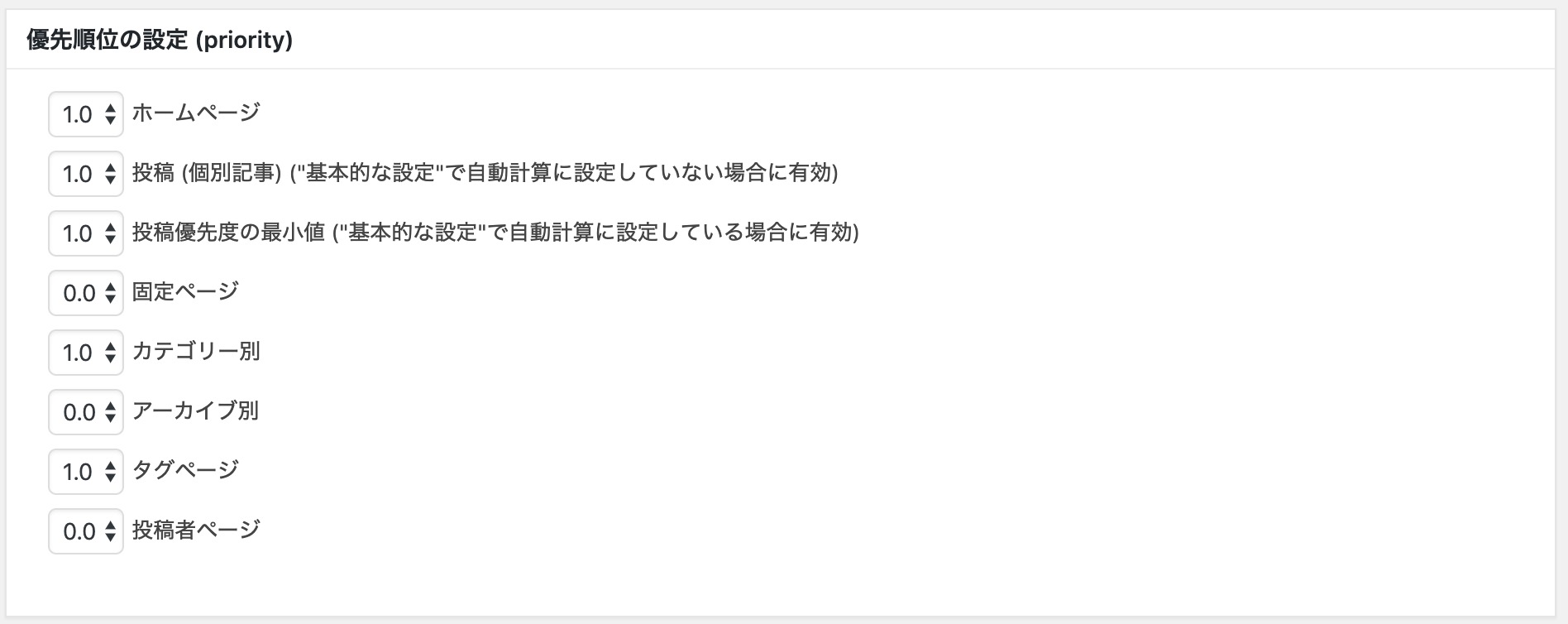
投稿の優先順位(領域)での設定方法
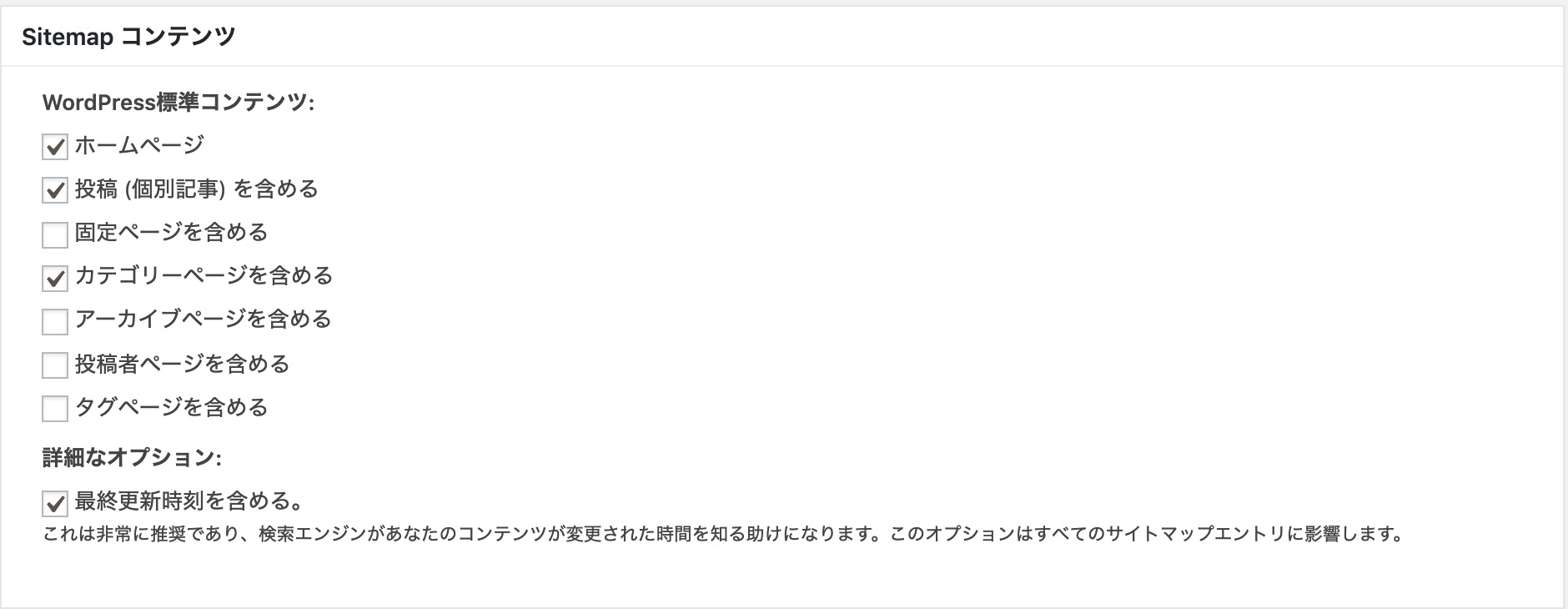
Sitemap コンテンツ(領域)での設定方法
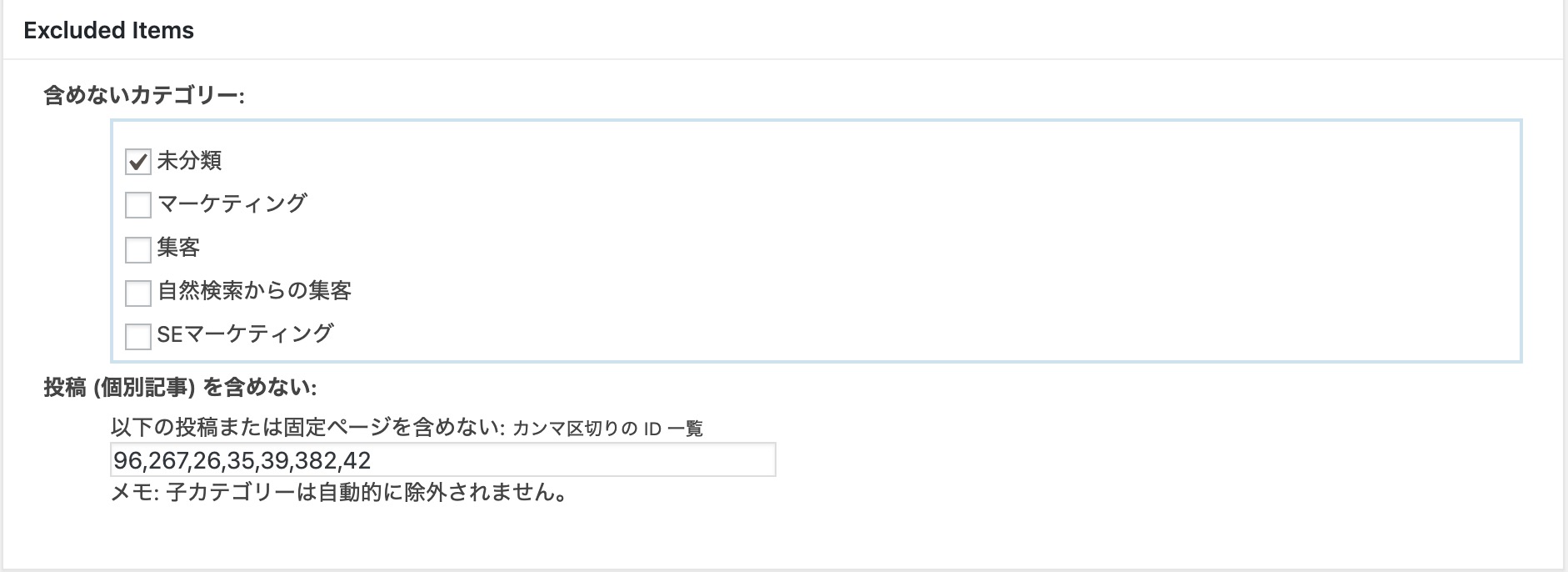
Excluded Items(領域)での設定方法
SEOを意識していないカテゴリーや個別記事、投稿記事を除外します。
基本的には個別ページは全てそのIDを入力して除外します。
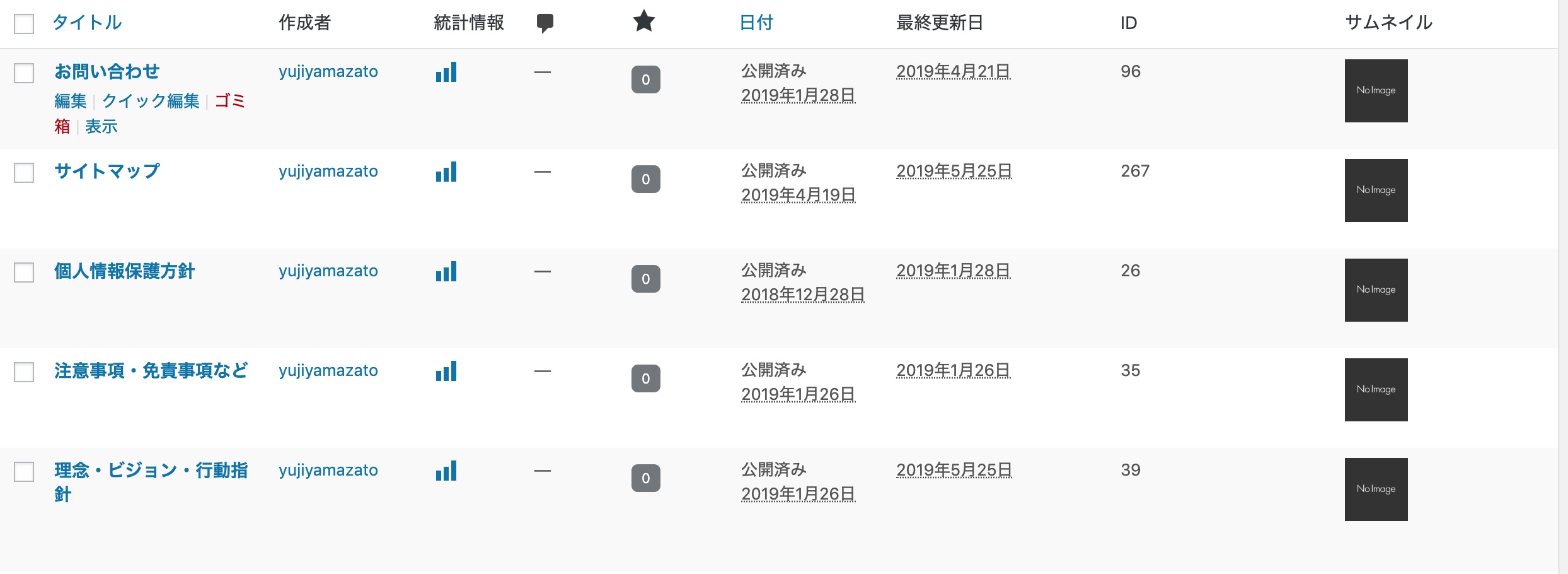
「IDはどこにあるの?」 と、思うと思うのでIDの場所は以下のスクショの通りです。
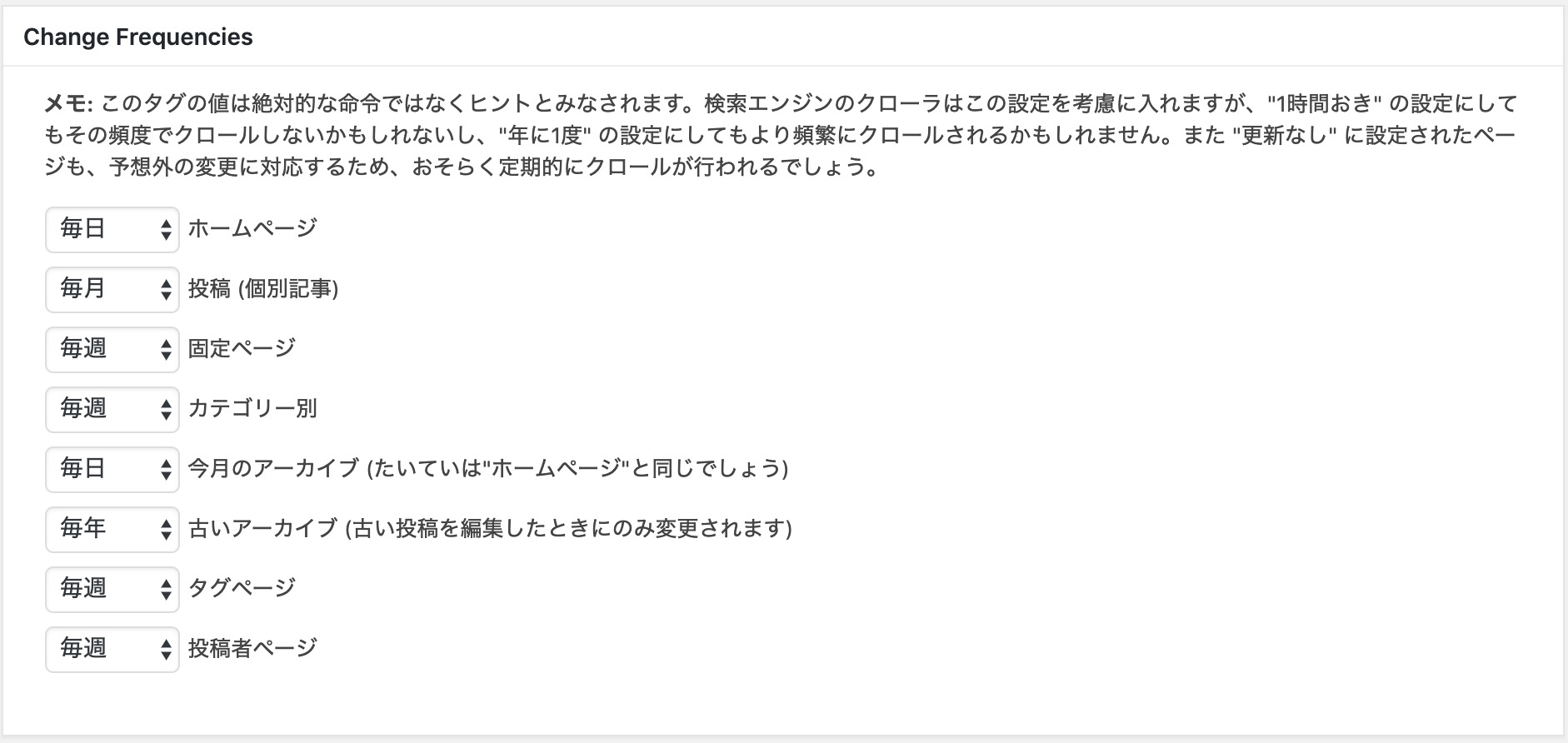
Change Frequencies(領域)での設定方法
優先順位の設定 (領域)での設定方法
Search ConsoleでXMLサイトマップを送信する
- 「設定を更新」をクリック
![Google XML Sitemap 設定更新]()
- Google XML サイトマップのサイトマップURLをコピー
![Google XML サイトマップURL]()
- Google Search Console にログイン。
- プロパティを追加 をクリック。
![Google サーチコンソル プロパティ追加説明画像]()
- 左のドメインを選択して、ドメイン”yujiyayamazato.com”などを入力。
![プロパティタイプ ドメインを選択]()
- TXT レコードを、ドメイン名プロバイダ(ドメインを取得したレジストラのこと)にログインして、
DNS 設定にコピぺし、サイトの所有権を確認する。各レジストラでの確認の仕方は、
ドメイン所有権の確認手順を参照。また、左のドメインでサイトの所有権を確認できな場合は、右のURLプレフィックスで行って下さい。![DNSレコードでのドメイン所有権の確認の説明画像]()
- 「確認」をクリック。ポイントは、所有権の確認をしようとしているドメインのネームサーバーは、そのドメインを取得したサイト(レジストラ、ドメインプロバイダ)のネームサーバーにした状態で確認をクリックすることです。そうしないと、エラーになってしまいます。確認ができた後は、ドメインのネームサーバーをサーバーのものにしておきましょう。例えばお名前.comでドメインを取得したら、サイトの所有権が確認できてからサーバープロバイダがさくらサーバーならば、ドメインのネームサーバーをさくらサーバーに変えてください。
- ②でコピーしたGoogle XML サイトマップのサイトマップURLを、
Google Search Console > サイトマップ にペーストして送信して下さい。![Google XML サイトマップURL]()
![xmlサイトマップとRSSをサーチコンソルに追加した画像]()

クローラー向けにRSS(feed)を作成・送信をし、クローラーを呼ぶ
All in One SEO Pack でRSS(feed)を作成しても良いですが、
この記事では、WordPressではせっかくRSS(feed)を標準搭載しているのでそれを活かしたいなと思います。
https://yujiyamazato.com にアクセスして、「メタ情報」を探します。
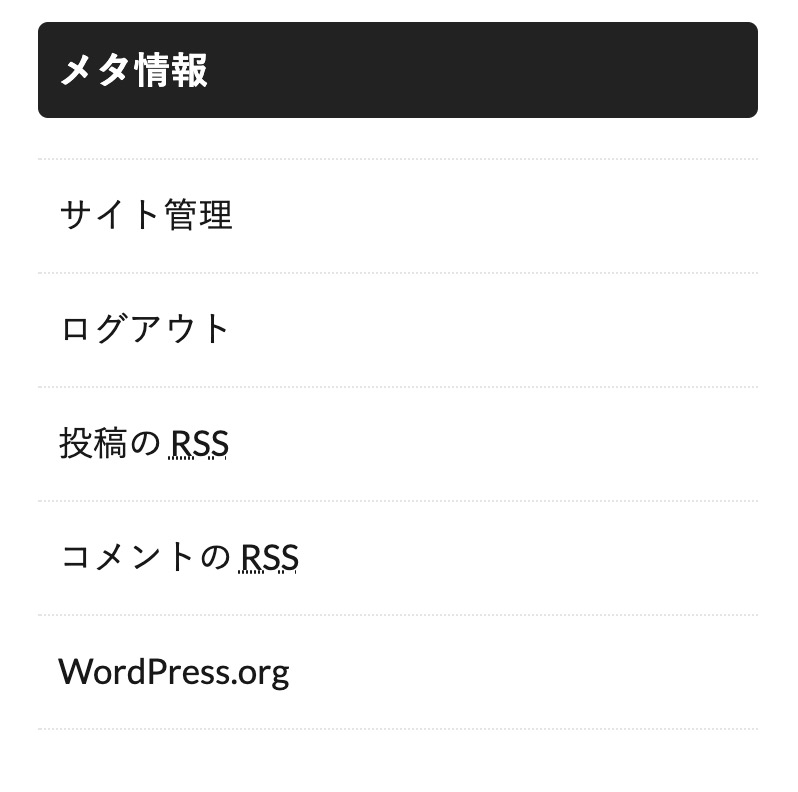
「投稿のRSS」につけられたハイパーリンク先URLが、RSS(feed)のURLなので
コピーして、Google Search Console > サイトマップ にペーストして送信して下さい。
呼び込んだクローラーをサイト内で効果的に巡回させる
https/httpを正規化・統一(重複ページの解消)
httpとは、
という記事にあるように
htmlなどのコンテンツの送受信に用いられる通信プロトコル(規約)のことです。
対して、httpsとは、SSLを利用したhttp通信です。
SSLとは、
- 通信内容を秘匿する暗号機能
- 通信相手の真正性
- 通信データが改ざんされていないか検知
の3つの機能を持ったインターネット上でデータを暗号化して送受信する通信プロトコル(規約)のことです。
簡単にいえば、httpは暗号化なし、httpsは暗号化ありです。
Googleは、https・暗号化されたwebサイトを推奨していますので、極力webサイトをhttps・暗号化して下さい。
暗号化の仕方は以下の記事に載っていますが、僕の環境がそうなので、
![]() お名前.comでドメインを取得して、レンタルサーバーはさくらのレンタルサーバを契約した方にオススメの記事です。
お名前.comでドメインを取得して、レンタルサーバーはさくらのレンタルサーバを契約した方にオススメの記事です。
別の業者様のサービスを使っていたとしても、参考になることが書かれていたりもするので読んでおいて損はしませんよ(笑)
以下の記事さえ読めば、https/httpの正規化・統一は簡単に行えます。
www有無を正規化・統一(重複ページの解消)

- site:rakuten.co.jp
- site:www.rakuten.co.jp
と、検索してみて下さい。
www有りも、www無しも、検索結果に出てきてしまうのなら
Googleから重複コンテンツとみなされて、検索順位を下げられてしまいます。
なので、webサイトをwww有り/www無し、どちらで運用するか決めた後に統一して下さい。
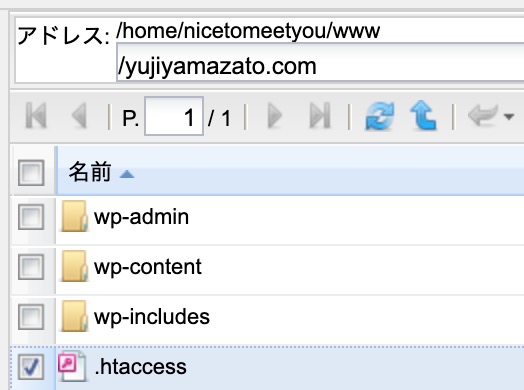
このサイトは、ソースコードは以下です。
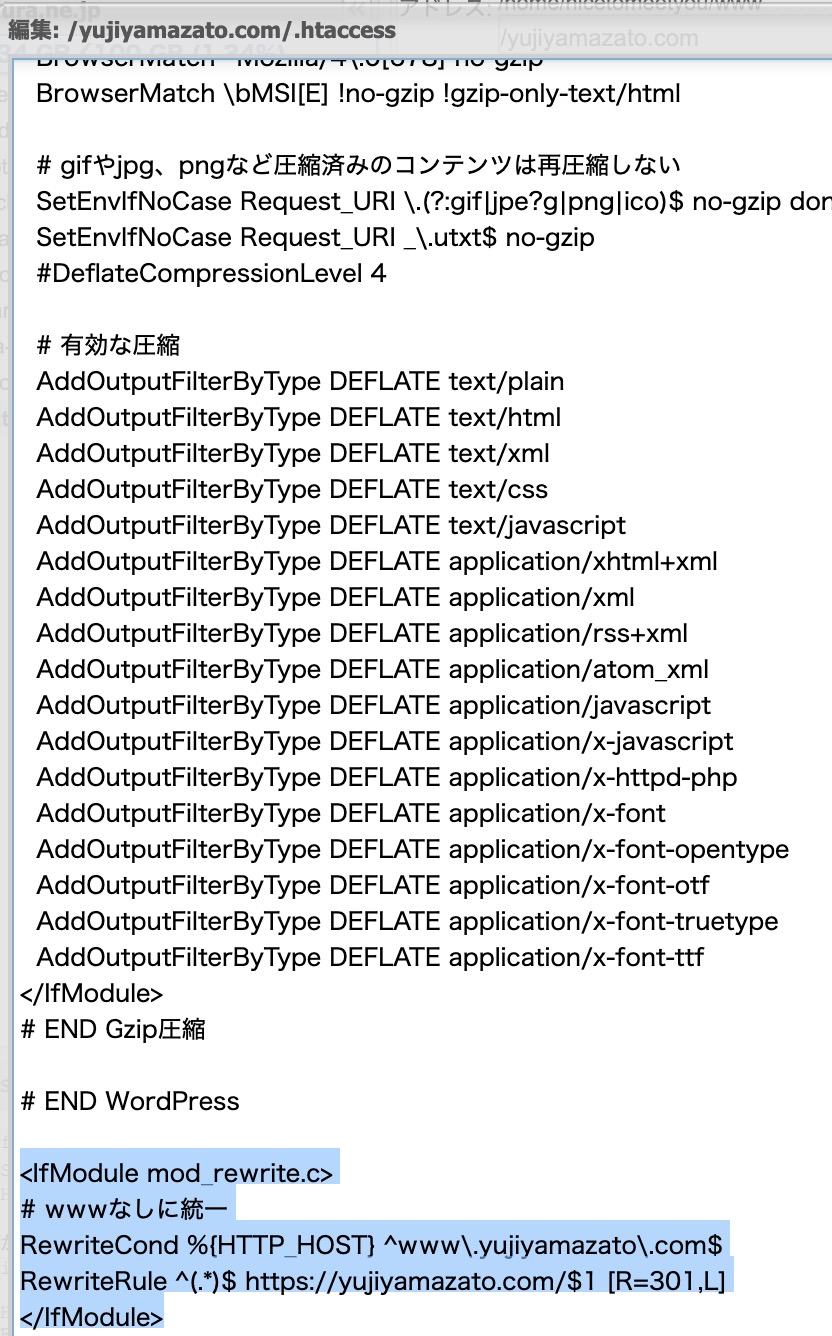
<IfModule mod_rewrite.c>
# wwwなしに統一
RewriteCond %{HTTP_HOST} ^www\.yujiyamazato\.com$
RewriteRule ^(.*)$ https://yujiyamazato.com/$1 [R=301,L]
</IfModule>
このソースコードをコピーして、.htaccessに貼ります。
index.html有無を正規化・統一(重複ページの解消)
これも同じく、以下のソースコードを.htaccessに貼ります。
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteBase /
# index.phpにアクセスできないようにする
RewriteRule ^index\.php$ - [L]
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule . /index.php [L]
</IfModule>
不要なパラメータを正規化・統一する(重複ページの解消)
以下の記事が有益なので、参考にして下さい。
重複ページを解消する(タグの改善)
新しいGoogle Serch Console でのHTML改善のドキュメントがないので出次第更新します。
パンくずリストを設ける
パンくずリストとは、以下の画像の
![]()
「HOME »記事一覧 »キャリアプラン »習慣を変えて未来を変える!新習慣の取り入れ方」の部分のことです。
パンくずリストをwebサイトに設けると、クローラーも訪問者も、現在webサイト内のどの階層にいるのか?が分かりやすくなるので、設けておきます。
パンくずリストを導入するには、WordPressでwebサイト作る場合は既にパンくずリストが組み込まれているテーマを購入するか、0から業者に作って貰うのであれば、導入できる業者に依頼します。
WordPressのテーマで、パンくずリストが組み込まれていない場合はこのプラグインをインストールすると導入できます。 Breadcrumb NVX
内部リンクを改善させる
例を挙げて説明します。
【望ましい内部リンク例】
soft bankのwebサイトのトップページから、
「https://www.softbank.jp/corp/set/data/news/press/sbkk/2019/20190328_01/pdf/20190328_01.pdf」
へのハイパーリンクにかかった、ハイパーテキスト(アンカーテキスト)は
九州電力エリアでの「ソフトバンクでんき for Biz」料金改定について(PDF形式) です。

つまり、「この記事」や「こちら」のようなテキストを使うのは避けて下さい。
アンカーテキストは、リンク先を簡潔にまとめたものにして下さい。
また、URLをそのままアンカーテキストにするのもダメです。
外部リンクを改善させる
外部リンクには、2種類あります。
- 発リンク:自分のwebサイトから、→他のwebサイトへのリンク
- 被リンク:他のwebサイトから、→自分のwebサイトへのリンク
発リンクのアンカーテキストも、内部リンクと同じように設定して下さい。
それに加えて、外部リンク先(他のwebサイト)が
- リンク切れ(404 Not Found 等)はNG
- アフィリエイトリンクやペナルティを受けているサイトもNG
特に②の、発リンク/被リンク、特に被リンクはすぐに自分のwebサイトへの被リンクの削除を依頼するか、
できなければバックリンクを否認するを参考に否認して下さい。
バックリンクとは、被リンクの別名です。
Googleにおいて、発リンクより被リンクの方が重要なので被リンクの質が悪いと検索順位が大幅に下げられます。
クロールが不要なページはrobots.txtで指定する
Googleにインデックスさせる必要のないページ(上位表示する必要のないページ)は、
クローラーが巡回しないように設定して下さい。
例えば、以下のようなページです。
- サイト内検索の表示ページ
- 404ページ
それ以外のページで使うことはありません。
しかし、WordPressを使っている人は特に何もする必要がありません。
demo.com/robots.txt と検索してアクセスした後に
以下のソースコードを確認できたら完了です。
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php Sitemap: https://demo.com/sitemap.xml
適切なインデックスを施す
基本のタグは、html・head・body
html文書ではhtml・head・body の3種類のタグが土台になっています。
<タグ>を「開始タグ」、</タグ>を「終了タグ」と呼びます。
開始タグと終了タグの間には、必ず他のタグか文書が入っています。
間に入っているものを、タグの中身と呼びます。
<タグ>タグの中身</タグ> この1セットの塊を、要素と言います。
また、<meta name=”description” content=”文書の内容を表す文章”> のように終了タグを使わないタグも存在します。
全てのサイトは、細かいタグを除くと以下のような順で言語を使って組み立てられています。
<html> <head> <title>文書のタイトル </title> <meta name="description" content="文書の内容を表す文章"> <meta name="keywords" content="キーワード,キーワード"> </head> <body>文書の本体 </body> </html>
htmlタグ
htmlタグとは、<html>と</html>に挟まれた文書が、
html文書であることを宣言するタグです。
headタグ
headタグとは、<head>と</head>に挟まれた文書が、
文書の情報を宣言するものであり、htmlタグの後、bodyタグの前に書くタグです。
通常、ブラウザ上に表示されません。
headタグ内にある他のタグ
headタグ内に使われるタグは多くありますが、
主要なタグは、「title」「meta」「link」「script」です。
1・titleタグ
titleタグだけ、ブラウザで表示されます。
2・metaタグ
metaタグとは、webページの情報を、検索エンジンやブラウザなどに伝える為のタグ。
人が見ることは基本ありませんが、ライバルが参考用に見ることはあります。
色々なmetaタグがありますが、主に以下の二つのmetaタグを押さえておけばいいです。
- meta descriptionタグ
- meta keywordsタグ
3・linkタグ
linkタグとは「とあるwebページ」と「他のwebページやファイル」を関連づけるためのタグです。
【例1】
例えば、とあるwebページがあって、以下のlinkタグがあるとします。
<link rel=”stylesheet” href=”〇〇.css”>
“rel”が、「relation」の略で、どんな関係かと行ったら
href=”〇〇.css” つまり、URL先の、”〇〇.css” は、とあるwebページの
“stylesheet” である。ということです。
hrefは、ハイパーリンクの参照という意味です。
【例2】
https://yujiyamazato.com/ というwebページに以下のlinkタグがあるとします。
<link rel=”canonical” href=”https://yujiyamazato.com”>
canonical は、「正規の」という意味があるのですが、
はアクセスして見れば同じサイトなのですが、検索エンジンとしては
違うwebページとみなされ、重複コンテンツとみされて評価が下げられてしまいます。
他にも、webページを長年運用して行くと、過去に「seo 内部対策」と書いたことを忘れて、
また「seo 内部対策」と書いてしまった場合に、liink rel=”canonical” を使うことがありますが、
この場合は、過去に書いた記事に、誤って書いた新たな記事の中で、
過去に書いた記事で書いていない部分だけ、文書として追記しておけば良いです。
canonicalタグの使い方 は、左のリンクを参考にして下さい。
4・scriptタグ
scriptタグとは、html内にスクリプトを埋め込むためのタグです。
そもそも、スクリプトがわからないと思いますので説明します。
先ずはプログラムを作って、コンピューターが動く流れを説明します。
a:コンピュータにさせたいことを、人間が理解できる言語で書く
aのことを、プログラミングと言います。
※ちなみに、計算表現能力のある言語がプログラミング言語であって、
htmlはマークアップ言語なので、プログラミング言語ではありません。
※補足
有名なプログラミング言語・・・
Ruby、Swift、JavaScript、PHP
b:aで書いたプログラミングを、コンピュータが分かる言語に翻訳する
プログラミング言語は、人間に理解はできてもコンピュータでは理解できません。
これを、コンピューターでも分かるようにすることを、コンパイルと言います。
c:bにしたがって、コンピュータにさせたいことを実行させる
です。
a:プログラミング → b:コンパイル → c:実行
という順番ですが、勝手にコンパイルもしてくれるプログラミングを、特にスクリプトと言います。
厳密に言えば、コンパイルもするようにプログラミングされたプログラミングの一つです。
つまり、扱うのが優しいプログラミング言語のことなのですが、優しくなると、用途が狭まるのが特徴です。
(簡単スマホを想像すれば分かり易いかと思います。)
例えば、JavaScriptは、インターネットの環境がないと動作しません。
ここで、html、css、スクリプト これら3つの関係性を書きます。
webサイト・webページは、これら3つでできています。
htmlが、webサイト・webページの土台で、それと同時に検索エンジン・クローラー・webブラウザなどのプログラムを作動させるために必要な情報です。
cssが、人間に視覚的に分かり易く理解させる為のwebデザインの部分です。
静的(動画のように動きがない様)な表現しかできないhtmlを補うように、動的な表現をさせることができるのがスクリプトです。
※スクリプトの具体例・・・
・使えない文字が入力された時に、ポップアップで知らせてくれる
・you tube
※補足・・・
JavaScript (ジャバ スクリプト) とは
WEB上でインタラクティブな表現をする為に開発されたオブジェクト指向の
スクリプト言語(簡易プログラミング言語)です。
HTML内にプログラムを埋め込むことで、Webページに様々な機能を付加できる
(Webブラウザの動作を定義できる)為、HTMLやCSSでは表現できないユーザーの動きに応じたものを作ることができます。(マウスの動きにあわせてデザインが変化する複雑なWEBページを作り出すことができます。)
従来Webページは、印刷物(紙に印刷された本)のような静的な表現しか作れませんでしたが、JavaScriptの登場により幅広い表現(動的表現)が可能となりました。
bodyタグ
bodyタグとは、<body>と</body>間に、文書の本文を宣言するものであり、
実際にブラウザに表示される文書の本体を記述します。
headタグ内のタグの使い方
titleタグ
titleタグは、h1タグと同じとみなして良いので以下のリンクをクリックしてご覧下さい。
meta descriptionタグ
meta descriptionタグとは、タイトルと共に検索結果で表示される
そのwebページの要約部分をしてするタグです。
「meta descriptionタグ」と検索すると、以下のようになりますが、
meta descriptionタグで指定されたテキストは、赤枠内に表示されます。
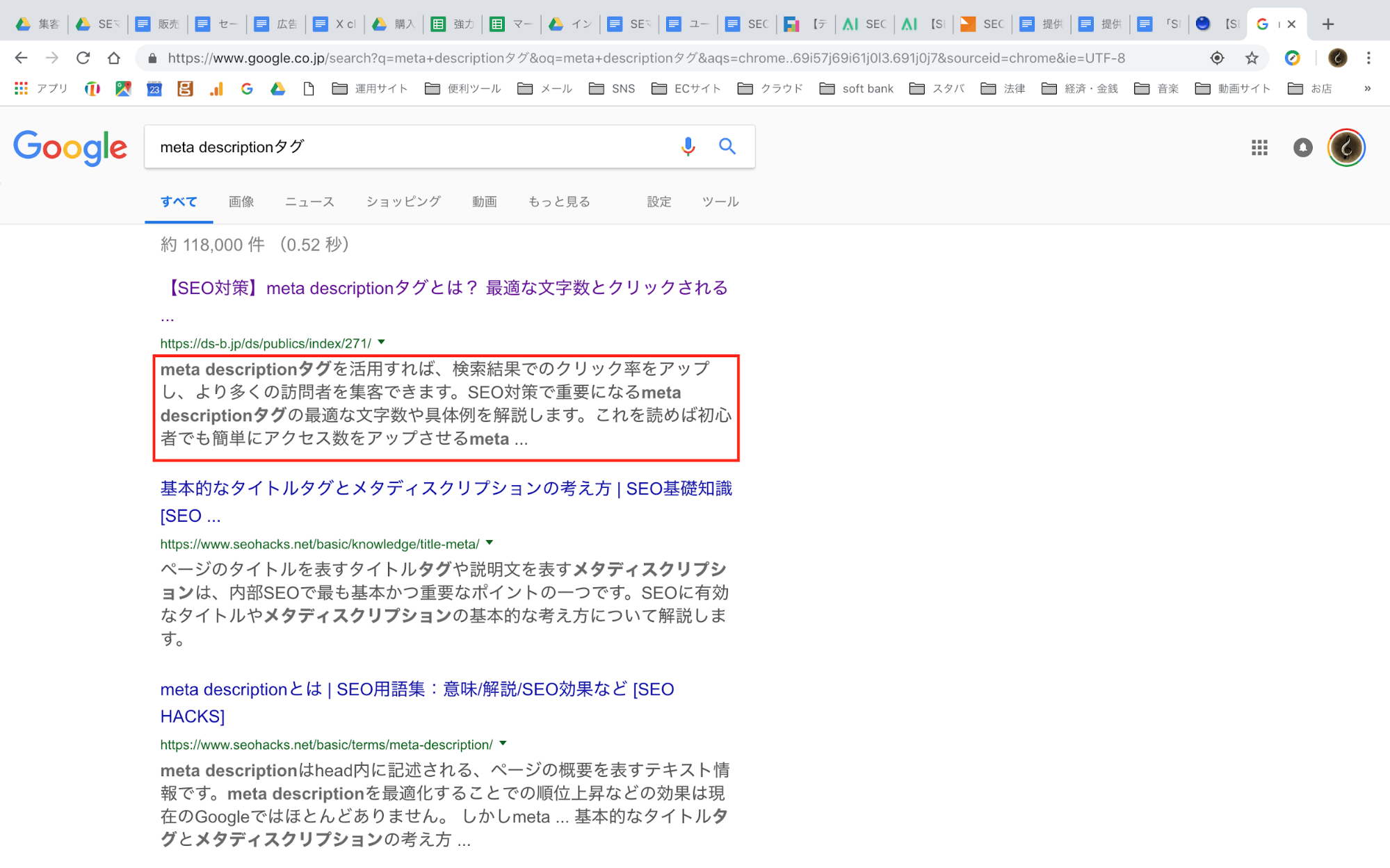
クローラーは、meta descriptionタグで指定されたテキストからwebページを理解します。
meta descriptionタグは、titleタグ、h1タグと共に検索結果に表示されて、
実際に検索した人の目に触れるので、クリック率に影響がある箇所でもあります。
検索結果には、windows PC、Macでは120文字前後のテキストが表示されますが、スマホでは50文字前後のテキストしか表示されません。
なので、50字前後で本質を突いた要約を書くようにしましょう。
但し、meta descriptionタグを適当に書くくらいならここが空欄でも、googleが自動的に<body>と</body>に挟まれた文書の本文を表示させます。
meta keywordsタグ
meta keywords属性タグとは、ページの内容をキーワードで示しているタグです。
これを見て、検索エンジンはページの中身が何であるかを理解していました。
例)<meta name=“keywords” content=“キーワード1,キーワード2,キーワード3” />
しかし、今ではもうGoogleはこの meta keywords属性タグを検索順位決定の大きな要素にはしていません。
その理由は、Googleのクローラーが進化して、meta keywords属性タグでwebサイトを判断するのではなくて、webサイトのコンテンツそのものの良し悪しを判断できるようになったからです。
なので、webサイト製作者はmeta keywords属性タグをクローラーに対してwebサイトを伝える一要素として捉えましょう。
bodyタグ内のタグの使い方
hχタグ
hχ(見出し)タグは、検索エンジンにwebページ・webサイト内のコンテンツ(文書など)を理解させ易くするためのタグです。
実際に「見出しタグ」と、検索して出て来たサイトで説明します。
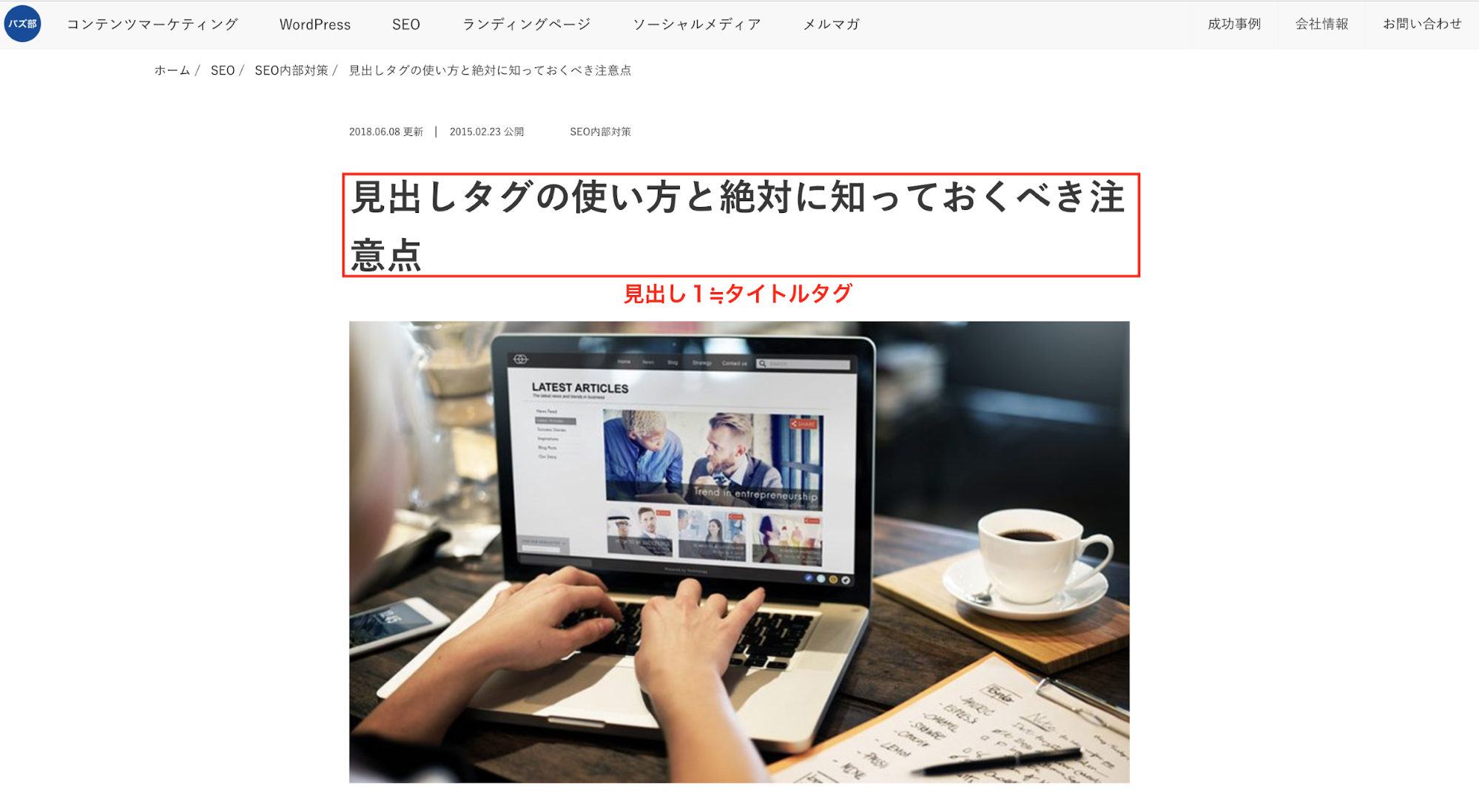
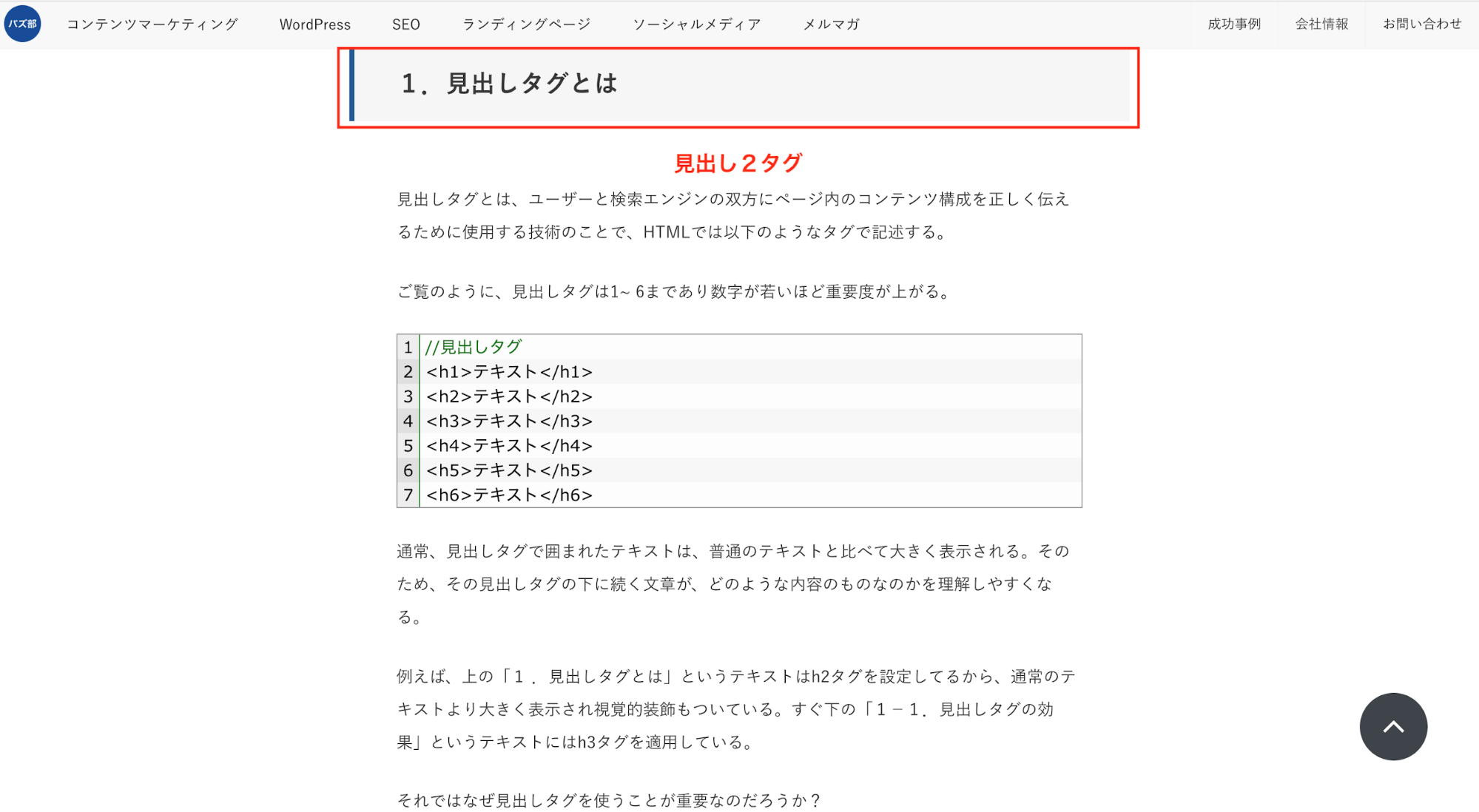
僕が説明しなくとも、見出しとは何なのかわかったかと思いますが、人向けには、文字を大きくしたり、色を付けたりして文章を読み易くできますが、
クローラー・検索エンジンは人間ではないので、代わりに見出しタグで伝える必要性があります。
見出しタグは、<h1>から<h6>まで6種類あり、<h7>以降はありません。
<h1>が最も重要で、下がって行って<h6>まで。
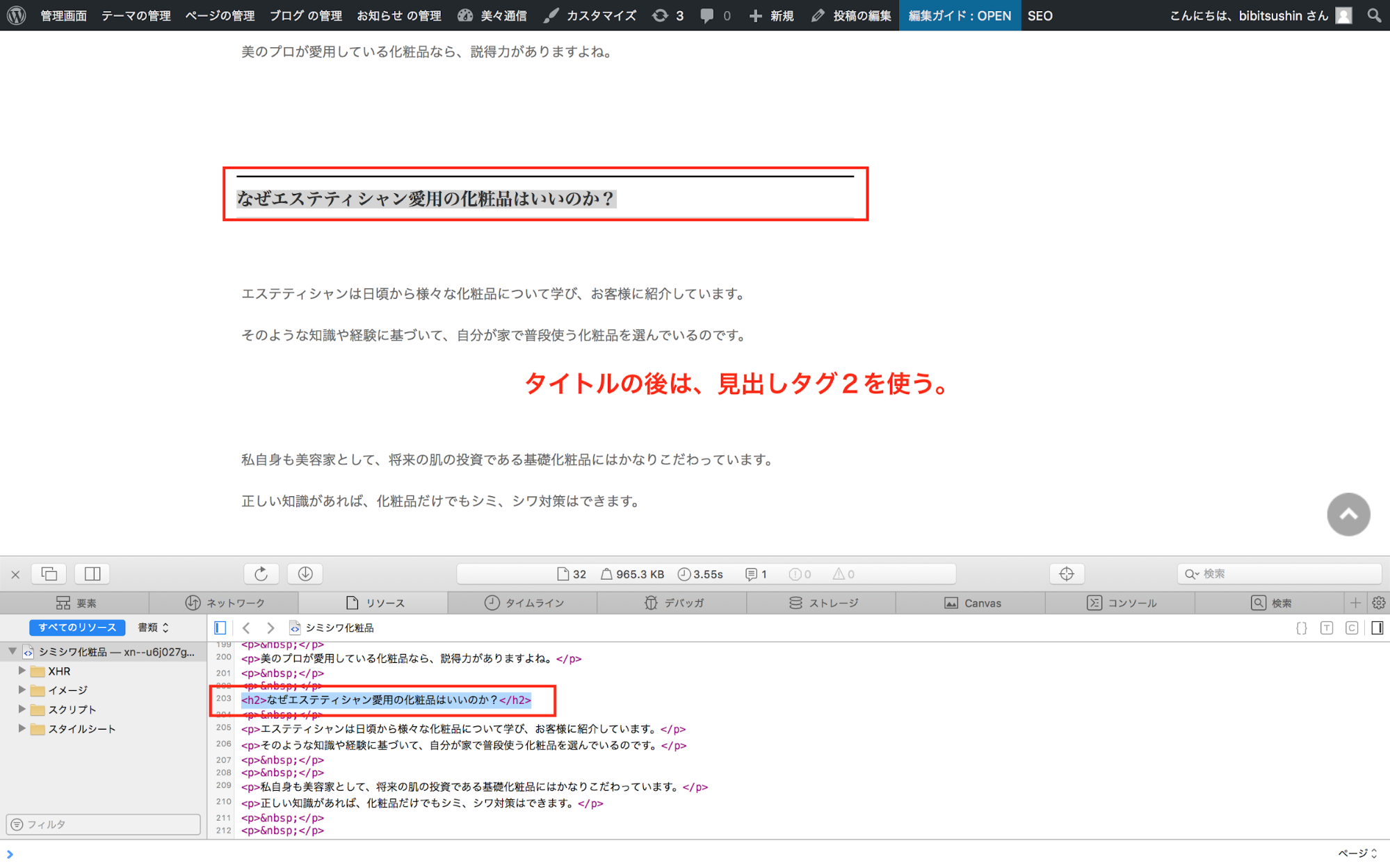
クローラーには、以下のように見出しタグを文書の起承転結を認識させます。
//見出しタグ <h1>テキスト</h1> <h2>テキスト</h2> <h3>テキスト</h3> <h4>テキスト</h4> <h5>テキスト</h5> <h6>テキスト</h6>
hχタグを使ったテキストには、ユーザー向けに見た目を変えてやる必要があり、
見出しを使ったら、CSSコードを使って文字のデザインが変わるように設定したり、
文字の大きさが変わるように設定する必要があります。
なので、hχタグを使って文字が変わるのは、hχタグの影響ではなく予めそうなるようにCSSコードで設定してあるからです。
<h1>が最も重要で、<h1>に近くなるほどそれに比例して
人に分かり易く理解させる為に文字が大きくなったり、デザインが派手になります。
hχタグに使える、デザイン集はこちら。
hχタグの使い方・注意など
h1タグ特有の使い方
h1は、大見出しとも呼ばれ、検索エンジンがページの全体の内容を理解する為に重要なタグです。
titleタグとほぼ同じ機能を持ちます。
つまり、<h1>(記事タイトル)</h1>。
(ちなみに、titleタグは<title></title>)
この<h1>タグだけ、他の<h2>~<h6>と違って、
titleタグと同じなのでページ内で1回しか使ってはいけません。
h1タグ、titleタグはとても重要なタグで、h1タグ、titleタグに選定キーワードが載っていないと検索エンジンでの上位表示は無理です。
h1~h6タグ全てに該当する点
1・【順番に使う】
悪い例
<h1>タイトル</h1> <p>テキスト</p> <h3>テキスト</h3> <p>テキスト</p> <h2>テキスト</h2> <p>テキスト</p>
上の表は、<h2>を飛ばして<h3>を使ってしまっているのでNGです。
良い例
<h1>タイトル</h1> <p>テキスト</p> <h2>テキスト</h2> <p>テキスト</p> <h3>テキスト</h3> <p>テキスト</p> <h3>テキスト</h3> <p>テキスト</p> <h2>テキスト</h2> <p>テキスト</p> <h3>テキスト</h3> <p>テキスト</p> <h3>テキスト</h3> <p>テキスト</p> <h4>テキスト</h4> <p>テキスト</p> <h3>テキスト</h3> <p>テキスト</p>
順番さえ守っていれば良いので、
<h3>テキスト</h3> <p>テキスト</p>
で、
<h2>テキスト</h2> <p>テキスト</p>
に戻らなくても大丈夫です。
2・【連続使用可能】
h1以外の、χの値が同じhχタグを連続で使っても大丈夫です。
実例を提示してのhχタグの使い方
ワードプレスでの実例のスクショで説明します。
「キーワード選定・タイトル付け・文書執筆方法」という記事の「文書執筆方法」の部分でも、実際に自分で書いた時にどこでhχタグを使うかを説明していますので、この記事もご覧下さい。
この「キーワード選定・タイトル付け・文書執筆方法」という記事が、
SEO対策を完璧にしたのにも関わらずに
・順位が上がらない
・順位が上がっても稼げない
という原因を根本的に消すことができる「コンテンツ対策」の一部です。
正直、こんな記事を読むよりは先ずはコンテンツを作る方が先決だと思います。
SEO対策という行動より、コンテンツを作る行動をした方が良いです。
「どんなコンテンツを作った方が良いの?」とわからない人は、僕に質問して下さい。
下のスクショはログインし、その後ブログをクリックし、
「新規追加」or「ブログ(過去に下書きとして保存したり公開したブログ一覧)」
をクリックすると表示される画面です。
h1タグ(≒titleタグ)
赤枠内のタイトル入力ボックスにタイトルを入力すると、ここがタイトルになります。
これを、公開したのが下の画像になります。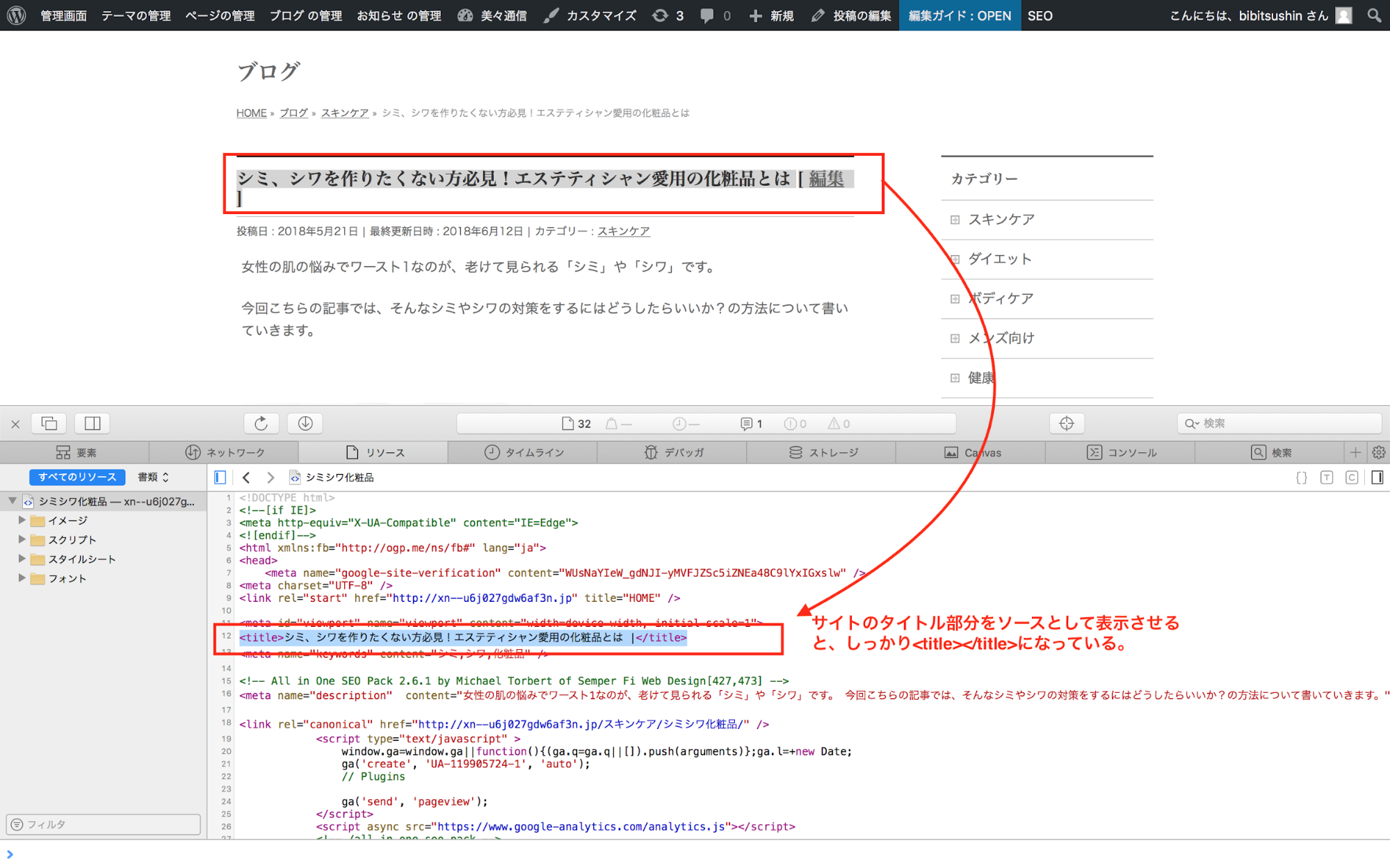

h2以降のタグ
既にタイトルタグを使っているので、h1タグは使いません。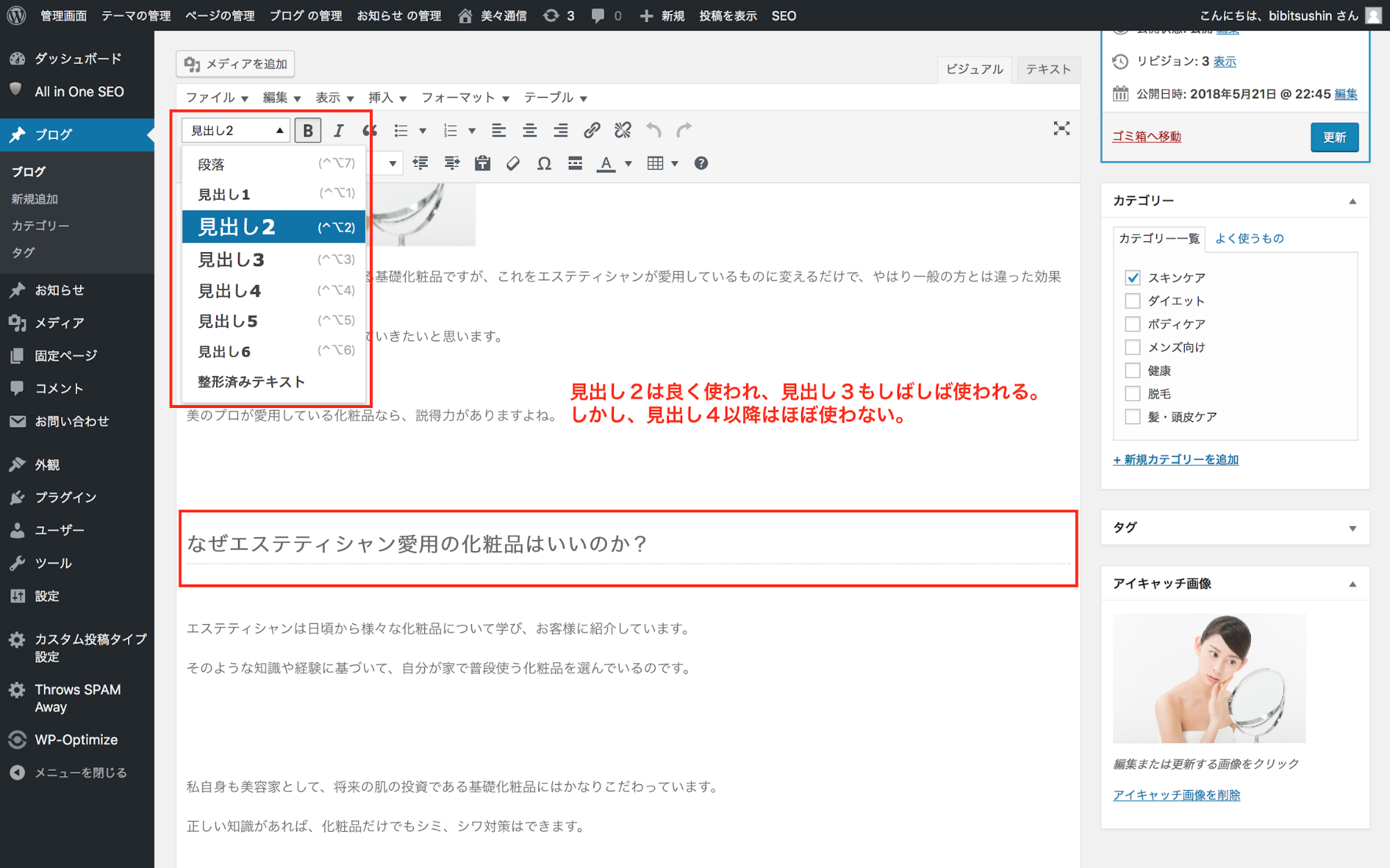
引用タグ
引用タグ(blockquote,q)とは、他のwebサイト、webページなどから文章を引用する際に使うタグです。
Googleは、
- コンテンツの無断複製
- オリジナルのコンテンツがほとんどまたはまったく存在しないページの作成
を、ウェブマスター向けガイドライン(品質に関するガイドライン)において禁止事項としています。
コンテンツの無断複製については、著作権法によって、著作物(コンテンツも含まれる)を作った瞬間に、著作権が認められるのでコンテンツの無断複製は、Googleで禁止されるだけでなく著作権を所有している人の複製権を侵害したとして、懲役や罰金に処せられます。
絶対に、しないようにして下さい。
1・長い文章を引用する時
blockquoteタグを使います。
2・短い文章を引用する時
qタグを使います。
3・引用元を明記する
引用する場合は、citeタグを使います。
citeタグには、属性タグと要素タグの2種類があります。
上記の1〜3の3つの見出し3については、

画像の最適化
画像の名前を、画像を簡潔に表した単語や文章にする
画像は、人が見れば何を表す画像なのかわかりますが、クローラーはわかりません。
画像が作成されるときは、自動的にその時の日時や、順番(1、2)などがその画像の名前になってしまいます。
そのままWordPressなどに上げるよりかは、どんなことを表している画像なのかを簡潔に説明した単語や文章に、画像名に変えましょう。
そうして画像名を付ければ、誰かが将来何かキーワードを画像検索した時にその画像名に合致していれば、画像経由であなたのwebサイトに行き着くことも考えられます。
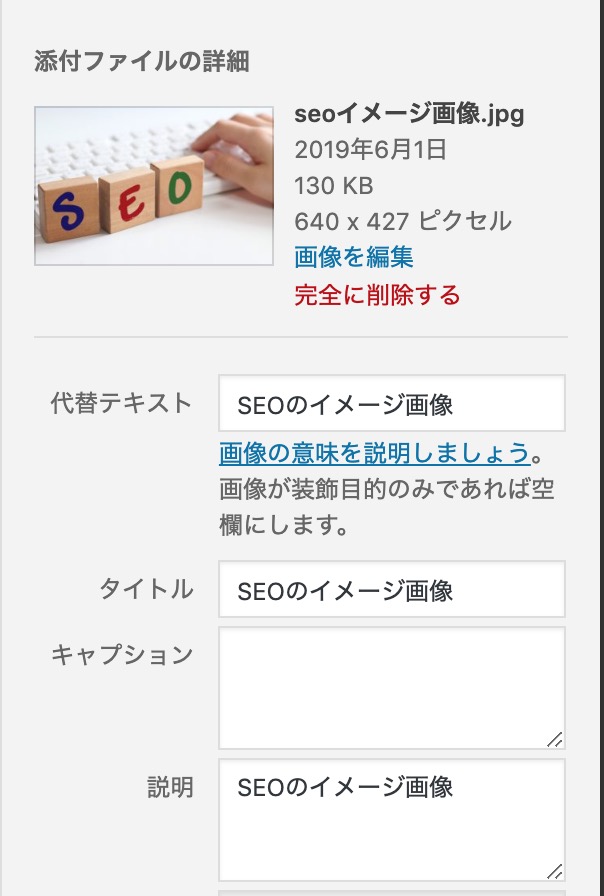
スクショのように、WordPressに上げた画像ファイルは、タイトル・代替テキスト・説明も設定しておきましょう。キャプションは、どちらでも良いです。

alt属性を設定する
alt属性とは、画像表示に必要なhtmlタグのimg要素プロパティのことです。
img要素とは、「今から、とある画像(とある画像のURL)を表示させますよ。」ということを宣言する要素のことです。
しかし、画像は人向けではテキスト(文書)より情報が多いのに対して
クローラーはロボットなので、画像が何を表しているのかをalt属性でクローラーに伝えます。
ソースコードは以下の通りです。
<img src=”画像 URL” alt="代替 テキスト">
alt属性を設定すると、テキストブラウザ(文章以外一切表示しないブラウザ)や
音声読み上げブラウザは、alt属性を読み込んでテキストで表したり、音声で表したりします。
このalt属性は、別名「代替テキスト」と呼ばれるもので、上の見出しで既に紹介しました。
noindexタグ
noindexとは、特定のURLを検索エンジンにインデックスさせないようにするための構文です。
noindexの記述されているURLは、原則としてどのようなキーワードで検索しても検索結果に表示されることがなくなります。
noindexが使用されているページは、検索結果に表示されなくなります。
noindexとは検索エンジンのロボット(クローラー)を制御するメタタグの一つで、検索エンジンに対して、該当するページを検索エンジンのインデックス(索引)へ登録しなくてよい、と伝える効果があります。
そのページのHTML内のhead要素に下記のnoindexメタタグを埋め込みます。
<meta name=”robots” content=”noindex” />
検索結果には表示されなくなりますが、ロボットによるページの巡回は行われます。
noindexと混同されがちなものにrobots.txtによるdisallowがありますが、こちらはロボットのアクセス自体を禁止するため、noindexとは異なります。
noindexされていてもロボットの巡回は行われるため、そのページにページランクが付くこともありますし、ページランクの受け渡しも行われます。noindexが指定されているページからのリンクは評価されます。
noindexの使用例
- 重複コンテンツ
- コピーコンテンツ
- 情報量の少ないページ
- HTMLサイトマップページ(リンク集のこと。)
- エラーページ
他には、作成中のページやテストページなどの完成していないページが検索結果に表示されるのを防ぐために使うことがあります。
但し、アップロードして公開する際はnoindexを外すのを忘れないよう注意する必要があります。
なお、noindexを指定していながらもそのページからのリンクは検索エンジンにたどって欲しい場合、followのメタタグも入れることが望ましいです(必須ではありません)。
その場合、head要素に入れるタグは下記のようになります。
<meta name=”robots” content=”noindex,follow” />
注意点
検索結果に表示させないことは、基本的にはアクセスの流入が減ります。
そのため、noindexの使用は必要性をしっかり見極めて下さい。
noindexの使用のポイントは
- ページ自体は必要
- しかし、検索結果には表示させたくない
- robot.txtやベーシック認証で制御するまでのものではない
です。
no follow属性
nofollow(属性)とは、
「このページのリンクをたどらない」や「このリンクをたどらない」といった指示を検索エンジンに与える手段の 1 つです。
リンク先にリンクジュース(ページ評価)の受け渡しを無効化できる属性のことです。
(例)ページAからページBにリンクする場合。
ページBのURLを https://yujiyamazato.com/ とします。
ページAに、<a href=”https://yujiyamazato.com/” rel=”nofollow”>(ハイパーテキスト)</a>
という要素があった場合、
ページBがページAから受け取るリンクジュースは無効になります。
nofollowを設定することでサイトBへアクセスすることはできても、サイトAのリンクジュースはサイトBには受け渡されなくなります。
SEO上の恩恵を受け渡さない、と言い換えることもできます。
nofollow属性の使用を強く推奨する場合は?
信頼できないコンテンツを含むWebサイトへリンクする場合
悪質なサイト、反社会的なサイト、などのサイトに止むを得なくリンクする場合は必ずnofollow属性を使います。
もし使わなければ、それらのサイトへクロールが行きインデックスされて他の誰かの検索によって表示させられてしまうのと、自分のサイトの評価が下げられてしまうからです。
尤も、そのようなサイトへの発リンクは極力しない方が望ましいです。
有料リンク
有料リンクとは、ページランクや検索順位を意図的に操作することを目的としたリンクを金銭で獲得することです。
有料リンクはGoogleが禁止しています。
クロールの優先順位
検索エンジンは、IDやパスワードを用いて登録やログインをすることができません。
なので、ログイン画面や注文フォームなどをnofollow指定しておくことで、クロールしなくなります。
nofollow属性の指定方法について
nofollowを指定するには、
- 特定のリンクに対して設定する方法
- metaタグに設定する方法
の2通りの指定方法があります。
2つの方法は、記述の方法だけではなく意味自体が異なりますので違いを説明しながら解説していきます。
特定のリンクに対して設定する方法
先ほども書きましたが、
(例)ページAからページBにリンクする場合。
ページBのURLを https://yujiyamazato.com/ とします。
ページAに、<a href=”https://yujiyamazato.com/” rel=”nofollow”>(ハイパーテキスト)</a>
という要素があった場合、ページBがページAから受け取るリンクジュースは無効になります。
metaタグに記述する方法
先ほどは特定でしたが、
metaタグにnofollow属性を記述すると、ページ内にある全てのリンクに対しnofollowを指定することとなります。
(例)ページAから、ページB、ページC・・・にリンクする場合。
ページA内に、ページB、ページC・・・への複数のリンクが設定ある場合でも、
ページAのmetaタグ内に下記のタグを設定することで全てのサイトへのリンクをnofollowにすることができます。
タグ:<meta name=”robots” content=”nofollow”>
サイトの表示速度を上げる
Webサイトの表示速度が遅いと、再訪問してくれません。
ページが表示されるまで4秒もかかると、なんと75%もの人が二度とそのサイトに訪れなくなるという統計があります。
なので、遅くとも2秒以内に表示されるようにします。
まずはサイトの速度がどれくらいかをGoogleのツールである、PageSpeed Insights を使って調べられます。
主に、以下を施せばサイトの表示速度が上がります。
- 高機能サーバーを使う。
- 画像を圧縮する。
- CSSを外部化する。
- Javascriptを最適化する。
- CDN(コンテンツデリバリネットワーク)を使う。CloudFlareやjetpackなど。
- キャッシュ系プラグインを使う。W3 Total CacheやWP Super Cacheなど。
携帯電話端末向けにも最適化する
Googleは、Webサイトがモバイルフレンドリーかどうかを重視しています。
以下をお読み下さい。
お持ちのWebサイトのモバイルフレンドリー未対応ならば、モバイルガイドを参考にして最適化の作業を行って下さい。
お持ちのWebサイトがモバイルフレンドリーかどうかを調べるGoogleのツールであるので、
モバイル フレンドリーを使って調べられます。
また、携帯電話端末からのアクセスをかなり重視するならば、AMPの導入も検討するべきポイントです。
しかし、当ブログの現在のAMPに対する見解は、AMPに対応しようとすると
まだまだ出たばかりの仕様なので、これに対する記事も少ないので、当分の間は
コンテンツ対策に重きを置いて、空いた時間にPageSpeed Insightsを使ってサイトの速度を上げるべきだと思います。
大事なのはこのSEO内部対策を読む以上に、どうマーケティングするか?
どうコンテンツを作るか?どう収益化するか?が急務だと思います。
しかし、ここの収益化が最大に難しいのでお問い合わせ頂きまして
一緒に最短・最速で収益化を行いたいと思います。
また以下よりブログの無料購読ができます。
記事が更新される度にあなたのメールアドレスに最新のSEO対策と、
集客数・売り上げアップの為に役立つ記事をお知らせします。